시간은 빨리가도 월급날은 더디온다.. 혼공머신을 공부한 6주는 월급날 보다 더 긴 느낌이다. TT
책장속에 책을 볼 때다. 책을 주문할 때의 열정은 어디 갔는지.. 봐야지 봐야지 생각은 있는데... 내일 봐야지 내일 봐야지... 미루 둔 것이 어언 2년이 흘렀다. 작년 23년 6월에 본 혼공학습단 모집... 선정이 되었지만... 안했다...아니 못했다..
OO님, 혼공학습단 10기에 선정되신 것을 축하드립니다! 안내 사항을 확인해 주세요.
연말에 다시 모집 메일을 보면서..... 미안하면서도 이 번에 꼭 끝내리라 ... 1번의 공수표는 있어도 2번은 없다.. 맘 속 다짐을 한다.
[한빛미디어] OO님, 혼공학습단 11기에 오신 것을 환영합니다!
2. 시작하기전 내 맘속의 다짐.
다음 2가지를 꼭 실천하리라 다짐을 하고 시작을 하였다..
토요일 까지 학습한 것을 Posting 한다...이를 위해서는 금요일 부터 시작해야 한다.
쉴 때 못 쉬고,, 운동할 것 못하고,.. 시간을 내는 만큼 집중해서 보자..
지금까지 일 하듯..큰 뼈대를 먼저 잡은 후에 세부적인 내용은 천천히 이해하는 방식으로 진행을 하였다..
3. 공부 하면서 얻은 것
6번 금요일 또는 토요일 올리고.. 지각을 안했다!!!와우!!.... 아..나도 한다면 한다!!
미션을 하기 위해서 책을 열심히 봤다. 잘 이해안되는 것은 인터넷을 활용하여 어느 정도 이해가 될 수 있었다.
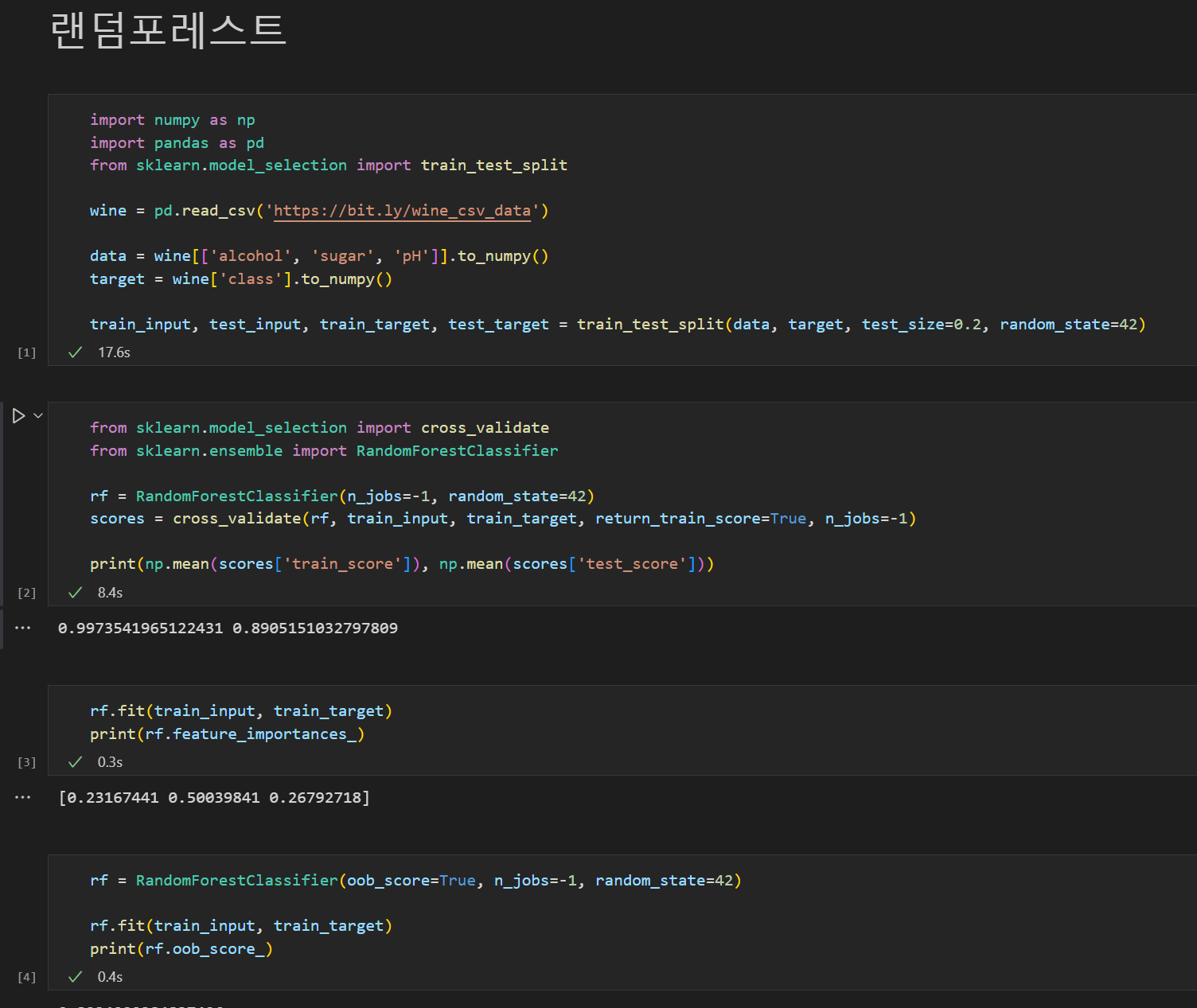
모델의 주요 개념, 모델의 속성을 이해했다.
책에 나온 소스의 주요 방법론을 이해했다.
Scikit-learn, numpy등의 라이브러리를 이해했다. numpy의 행렬변환이 어려웠었는데 많이 편해 졌다.
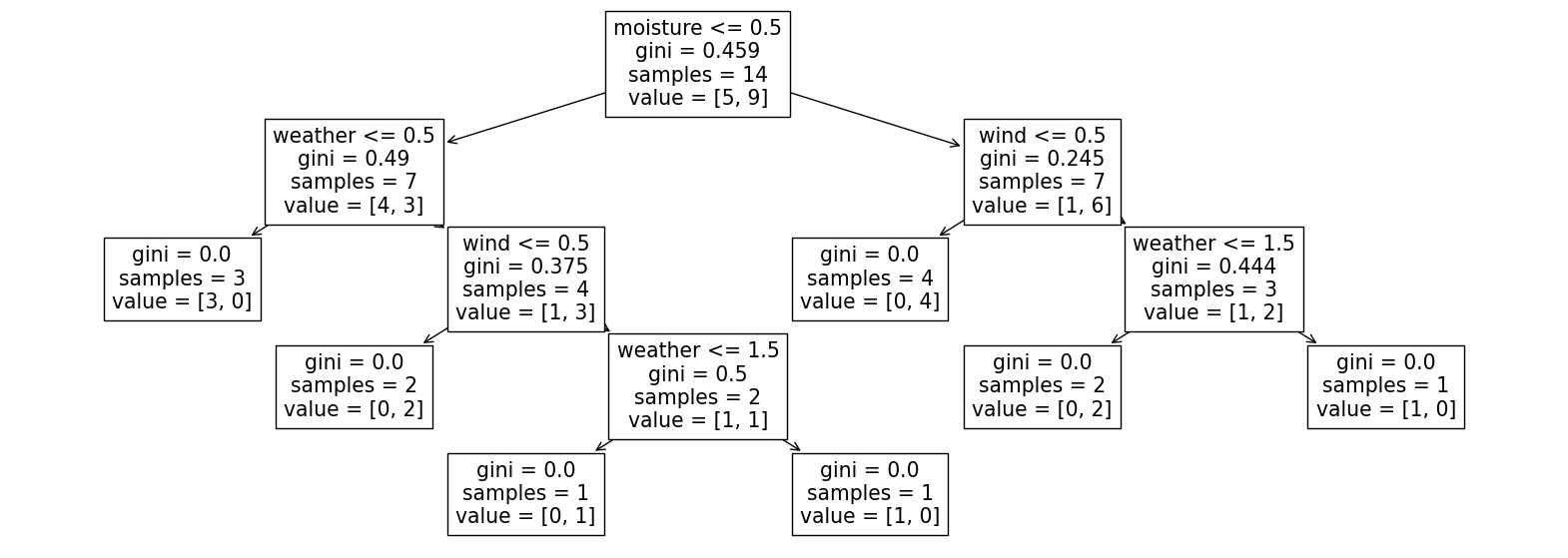
이해를 위해 책을 활용하여, 나름 확장하여 이것 저것 시험을 해봤다... Decision Tree의 Gini 계수 결정을 안 잊어버릴 것 같다..족장(리더)님의 열정에 자극 받아...아.... 해결했을 때의 쾌감!!!!
정리 글은 항상 책을 다 보고 머리에 정리해서 큰 클을 만들고, 필요 부분은 책을 보면서 정리를 해 나갔다..(나름 뿌듯!!)
4. 혼공 학습단에 참가하면서 얻은 것
족장님의 응원, 열정, 관심을 보면서 6주간을 학습한 것 같다
그 많은 혼공족의 게시글을 읽은 후에 답변을 다는 것을 보고 오!! 그대야 말로 정말 프로페셔널이군요... 그렇담 나도 열심히 해야 겠군... 생각하며 진행했던 것 같다.
4주차 Decision Tree를 학습하면서 올린 질문은 나름 같이 공부하는 혼공족과 고민을 하고 싶어서 올렸는데...족장님이 그렇게 애는 모습을 보면서... 포기하지 말고 찾아보고... 해결을 한 것이... 책을 보며 학습한 것보다 이번 혼공 학습단에 참가하면서 느끼고 배운 것이 컸군요... (당신이 갖고 있는 누군가의 관심이 큰 영향이 갈 수 있습니다.)
단순한 실수를 해결할 수 있었네요... softmax 함수를 정의하면서 혼자 왜 안되지 고민한 것을 discord에 문의하였더니 혼공족님의 도움으로 해결하였어요... 한참 고민했었는데.... ㅎㅎ.. 그러고 보니 해결해준 혼공족님에게 고마움의 표시를 못했네요..아... 칭찬의 방에 올려야 겠군요 ^^
다른 사람이 헷갈리면 나도 헷갈린다.
우연찬게 본 족장님의 게시글 pandas의 axis가 헷갈려요....나도 한때는 공부 했었는데...... 이렇게 보니... 저렇게 하면 되겠구나 했는데.... 곰곰히 보니 나도 헷갈린다... 아마도 사용할 때마다 블러그를 보고 그 때 그때 해결했던것 같군요..... 인터넷 뒤져서.. 나름 규칙을 만들고 정리했다...다음 차 공부할때 np에서 axis가 나왔다.. 역쉬 pandas나 np나 동일한 개념이였다...
처음 정리할 땐 나와 관련 없는 것인데 정리를 해 두니... 나도 잘 써 먹었다..
족장님이 쪽집게 처럼 모두가 어려워 할 문제를 이슈 제기를 잘 한 것 같다.. 이것도 고맙다..
생각을 정리하는 것이 어렵다.
머리속에 이해된 것을 글로 쓴다는 것이 어려움을 다시 느낀다..번역서를 읽으면 왜 이리 이해 안되게 어렵게 투덜 거렸는데... 나 역시 정리를 하면서 어려움을 느낀다...생각 정리를 블로그로 해야 하나? 고민중...
블로그/페북의 기능을 알아가다
그림 복사하기가 가능한 것을 알게 됨!!
블로그에 그림을 삽입할 때 항상 로컬PC에 저장한 다음에 올렸는데.... ... 요 기능 알고 나서는 유래카!!! 외침
서식쓰기 가능이 있다는 것을 알고 적용해서 사용해 봄.. 와우!!
페북 채팅이 별도 프로그램 설치 없이 가능하다는 것을 알게됨 (족장님은 DM이라고 하던데... )
5. 앞으로 계획
. 6주 학습기간에는 머신러닝은 이런거야를 배웠다면.. 맘에 품은 질문은 왜 이럴까? 어떻게 가능할까? 를 계속 진행할 예정입니다.
그래서 또 다른 머신러닝책은 구매 했고 읽을 공부할 예정이고,,, 수학은 아래 책을 볼까 생각중인데... 혹시 추천 책이 있을까요?? (아 이놈의 질문병..)
핸즈온 머신러닝 들어가기 전에,,, 수학적 기초 온라인으로 듣고 있습니다. 혼공머신이 마중물이 되어서 ML, 딥러닝, LLM을 더 많이 이해 하고 싶네요
0. 감사의 글
책상속에 묻힐 책을 꺼내어 학습 할 환경을 마련해 주셔서 감사합니다... 책을 통해서 알아가고 , 부족한 것을 느끼고, 또 찾아가려는 나를 흐믓하게 바라볼 수 있는 좋은 기회였습니다.
직장인이 기술 서적을 혼자 읽기에는 많은 한계가 있는데.. 학습단을 통해 한계를 극복 할 수 있었습니다.
경제적 지원을 해주시 출판사와 리딩 해 주신 족장님께 감사드립니다. 독자로서 이런 사회적 가치를 실천하는 출판사를 응원하게 됩니다.
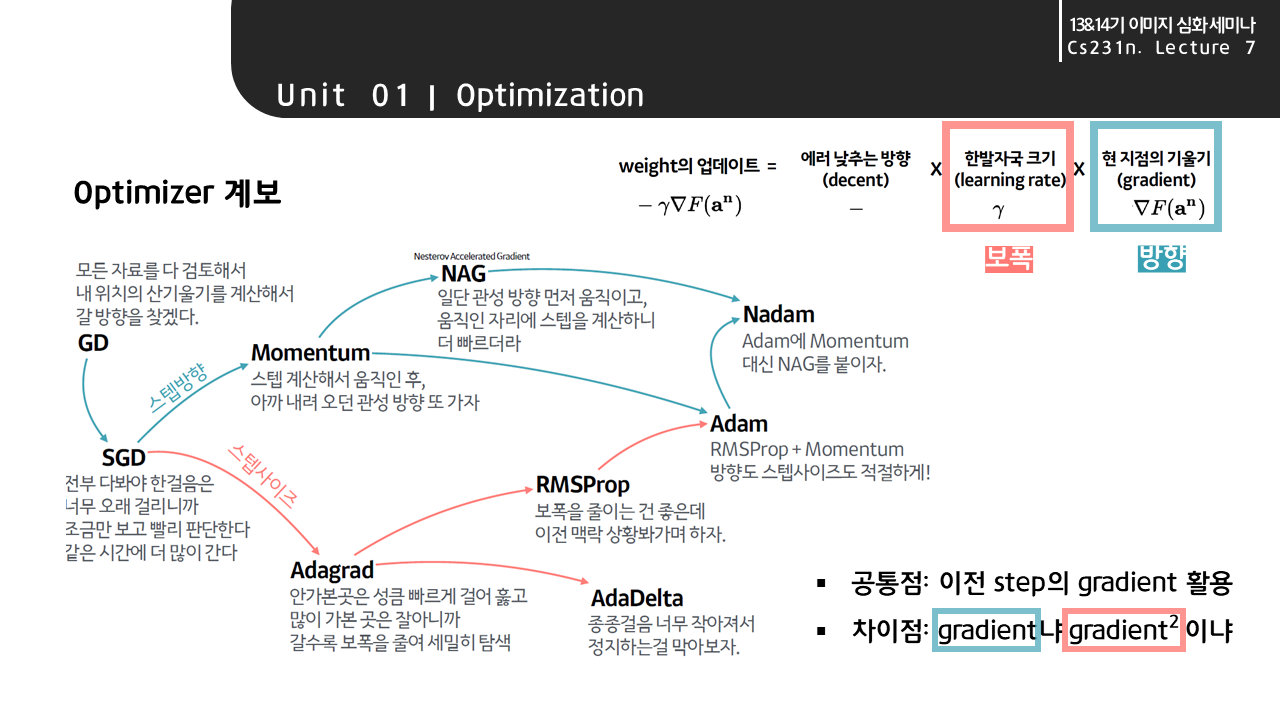
딥러닝을 이해하기 위해 지금까지 머신러닝을 공부하였구나 생각이 드네요..문제종류(회귀, 이진,다항분류..), 손실함수, 하이퍼파라미터 등..
1. 기본 개념도. 2.TensorFlow 기본 사용법.3 책의 예제로 입력/출력층으로 구성된 모델 살펴보기. 4. 다중 레이어로 구성된 모델 살펴보기로 정리를 해봤어요..
(아... cheatSheet 중간에 있음)
정리를 하다 보니 앞 부분에서 대충 넘어간 부분들을 다시 살펴볼 필요가 있네요... 그래도... 다시 봐야 하고 중점적으로 봐야 할지 느끼네... 아직 안개속에 있지만 안개가 희미하게 거치는 느낌!!!ㅎ
책을 살때의 매직.... 읽고 안 읽고는 나중 문제다.. 읽고 난 후의 모습을 상상하며 책을 산다....필독!!!
1. 주요 딥러닝 개념도
인간의 뇌를 본뜬 Perceptrons.. .
중간층은 입력값과 적절한 웨이트를 조절하여 새로운 의미의 속성을 표현한다고 개념적으로 생각하자.
만약 데이타가 세로, 가로라면 사람은 크기를 유추할 수 있다.
만약 데이타가 집의 크기, 침대 수, 우편번호, 거주자의 연봉이 있다면... 우편번호와 연봉으로 학교의 등급을 표현할 수 있다...
노드의 결과가 다른 노드로 전달할때 얼마의 값 으로 전달해야 할까? 활성화 함수..
이 노드의 결과는 다른 노드에 반영하지 말아야 해...아니야... 0.3만 반영해... 그렇지 않아... 음수로 반영해.....
결과 값을 찾았는데... 찾은 값이 오류가 있다고 판단을 하면,, 찾은 값을 증가 시켜야 할까?? 감소 시켜야 할까??
순전파 : 주어진 데이타로 결과를 찾는 방향...순방향
역전파: 결과를 찾았으면, 오류를 수정하기 위해....가중치를 수정한다..... 역방향..
Hyperparameters
은닉층의 수, 노드의 수, 활성화 함수, batch_size는 상황에 따라 지정해야 할 하이퍼 파라미터
다만, 결과층의 활성화 함수는 문제에 따라 정해져 있다!!
옵티마이저 역시 하이퍼파라미터임!!
RMS,SGD등
860~1,000 억개의 신경세포와 100조개의 신호를 주고 받는 시냅스
노드 또는 뉴런을 원으로 표기
예를 들어, 0.2와 0.9 두 개의 입력 값으로 0.5라는 예측값을 도출하는 인공신경망 모델을 학습시키는 과정을 생각해보겠습니다. 아래 그림과 같이 입력층에는 2개의 노드가 할당되며 출력 층에는 1개의 노드가 할당됩니다. 그리고 은닉층은 1개이며, 은닉노드는 3개로 임의로 설정합니다. 여기서 은닉층과 은닉노드의 개수는 다수의 반복실험을 통해 사용자가 적절하게 설정해야 하는 값입니다
활성화 함수
문제에 따라 사용되는 활성화 함수와 손실 함수
2. Tensorflow 기초 사용법
모델 생성이 기존 머신러닝보다 복잡합니다. 레이어를 생성해야 하고, 활성화 함수를 지정해야 하고, loss 함수등을 지정해야 하는군요... 파란색으로 표기된 모델 생성과 학습부분을 세부 공부를 해야 겠군요.
import numpy as np from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense
#데이타 생성 data = np.random.random((1000,100)) labels = np.random.randint(2,size=(1000,1))
#전처리
#모델 생성 및 학습 model = Sequential() model.add(Dense(32, activation='relu', input_dim=100)) model.add(Dense(1, activation='sigmoid')) model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['accuracy'])
model.fit(data,labels,epochs=10,batch_size=32)
#예측 predictions = model.predict(data)
#평가
from sklearn import neighbors, datasets, preprocessing from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score
#데이터 생성 iris = datasets.load_iris() X, y = iris.data[:, :2], iris.target X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=33)
#모델 생성 및 학습 knn = neighbors.KNeighborsClassifier(n_neighbors=5) knn.fit(X_train, y_train)
#예측 y_pred = knn.predict(X_test)
# 평가 accuracy_score(y_test, y_pred)
3. MNIST 패선 다중 클래스 분류
10종류의 60,000개의 그림을 분류 하는 예제. 하나의 그림은 28*28 크기의 2차원 데이타를 1차원으로 변환하여 사용함. 즉 그림 하나는 784 = 28*28 크기임
입력은 784, 히든 층 없이 결과층을 node=10로 만듭니다.
다중 클라스 분류이므로 sparse+categorical_crossentropy를 사용하고 출력층의 활성화 함수는 softmax를 사용합니다.
import tensorflow as tf
from tensorflow import keras
from sklearn.model_selection import train_test_split
from tensorflow.keras.utils import *
# 실행마다 동일한 결과를 얻기 위해 케라스에 랜덤 시드를 사용하고 텐서플로 연산을 결정적으로 만듭니다.
tf.keras.utils.set_random_seed(42)
tf.config.experimental.enable_op_determinism()
#데이타 갖고 오기
(train_input, train_target), (test_input, test_target) = keras.datasets.fashion_mnist.load_data()
#전처리...
#1. scaling
train_scaled = train_input / 255.0
#2. 데이타를 1차원으로 변경하기
train_scaled = train_scaled.reshape(-1, 28*28)
#데이타 사이즈 확인
print(f'데이타 크기 {train_scaled.shape}, 정답 크기{train_target.shape}')
# 학습/평가데이타 분류
train_scaled, val_scaled, train_target, val_target = train_test_split(
train_scaled, train_target, test_size=0.2, random_state=42)
# 모델 생성
dense = keras.layers.Dense(10, activation='softmax', input_shape=(784,))
model = keras.Sequential(dense)
model.compile(loss='sparse_categorical_crossentropy', metrics='accuracy')
# 모델 요약 정보 조회
model.summary()
plot_model(model, show_layer_names=False, show_shapes=True)
#모델 학습
history= model.fit(train_scaled, train_target, epochs=5)
#모델 평가
model.evaluate(val_scaled, val_target)
입력에 대한 갯수가 없어 100개 입력을 했는지 확인해 보겠습니다. 출력을 보니 맞군요..
사용된 코드는 아래와 같습니다.
# 모델 생성
dense = keras.layers.Dense(10, activation='softmax', input_shape=(100,))
model = keras.Sequential(dense)
model.compile(loss='sparse_categorical_crossentropy', metrics='accuracy')
# 모델 요약 정보 조회
model.summary()
# 모델 그림 그리기
plot_model(model, show_layer_names=False, show_shapes=True)
4. MNIST 패선 다중 클래스 분류 (다중 레이어)
하이퍼 파라미터인 은닉층 및 옵티마이저 추가하기
데이타가 28* 28 크기의 2차원 데이타를 Flatten Layer를 사용하여 2차원 데이타를 사용하기
3장에서는 np를 사용
import tensorflow as tf
from tensorflow import keras
from sklearn.model_selection import train_test_split
from tensorflow.keras.utils import *
# 실행마다 동일한 결과를 얻기 위해 케라스에 랜덤 시드를 사용하고 텐서플로 연산을 결정적으로 만듭니다.
tf.keras.utils.set_random_seed(42)
tf.config.experimental.enable_op_determinism()
#데이타 갖고 오기
(train_input, train_target), (test_input, test_target) = keras.datasets.fashion_mnist.load_data()
#전처리...
#1. scaling
train_scaled = train_input / 255.0
#데이타 사이즈 확인
print(f'데이타 크기 {train_scaled.shape}, 정답 크기{train_target.shape}')
# 학습/평가데이타 분류
train_scaled, val_scaled, train_target, val_target = train_test_split(
train_scaled, train_target, test_size=0.2, random_state=42)
# 모델 생성
model = keras.Sequential()
##데이타를 1차원으로 변경하기
## train_scaled.reshape(-1, 28*28) 대신 Flatten()를 사용한다.
model.add(keras.layers.Flatten(input_shape=(28, 28)))
model.add(keras.layers.Dense(100, activation='relu'))
model.add(keras.layers.Dense(10, activation='softmax'))
## Optimizer를 사용한다.
sgd = keras.optimizers.SGD()
model.compile(optimizer=sgd, loss='sparse_categorical_crossentropy', metrics='accuracy')
# 모델 요약 정보 조회
model.summary()
plot_model(model, show_layer_names=False, show_shapes=True)
#모델 학습
history= model.fit(train_scaled, train_target, epochs=5)
#모델 평가
model.evaluate(val_scaled, val_target)
답/라벨없는 데이터 내에서 거리가 가까운 것들끼리 각 군집들로 분류하는 것이다 (분류라고 표현했지만, 지도학습인 classification과는 다르다). 즉 데이터 내에 숨어있는 패턴, 그룹을 파악하여 서로 묶는 것이라고 할 수 있다. 만약 라벨값이 존재하는 데이터라고 하더라도, 같은 라벨 내에서도 얼마든지 다른 군집으로 묶일 가능성이 있다.
Clustering(군집화) : 비슷한 샘플끼리 그룹으로 모으는 작업
Cluster(클러스터) : 군집 알고리즘에 의해 만든 그룹
1 K-Means / K-평균
K-Means 클러스터링은 클러스터링에서 가장 일반적으로 사용되는 알고리즘으로, 군집 중심점(centroid)이라는 특정한 임의의 지점을 선택해 해당 중심에 가장 가까운 포인트들을 선택하는 군집화 기법이다. K-Means이므로 K개의 centroid를 지정한다. 이때 가장 가까운 포인트를 선택한다는 점에서 K-Means는 거리 기반 군집화 방법임을 알 수 있다
무작위로 k개의 클러스터 중심을 정한다.
각 샘플에서 가장 가까운 클러스터 중심을 찾아 해당 클러스터의 샘플로 지정한다
클러스터에 속한 샘플의 평균값으로 클러스터 중심을 변경한다.
클러스터 중심에 변화가 없을 때까지 2번으로 돌아가 반복한다.
2 K-평균 실습
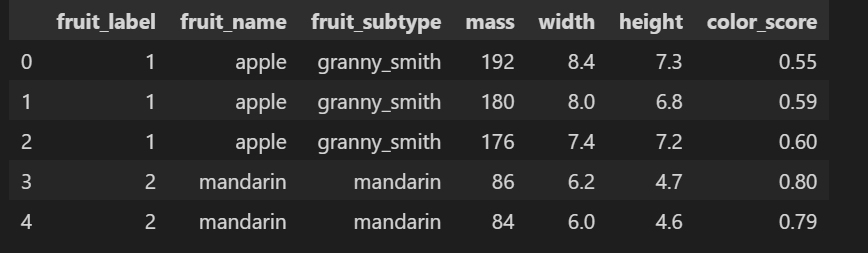
모델이 얼마나 잘 학습하고 있나 확인을 위해 정답을 갖고 있는 데이타를 활용하여 결과를 비교하자. 질량, 크기(가로,세로), 색상으로 구성된 4개의 속성으로 ['apple' 'mandarin' 'orange' 'lemon'] 4 종류의 데이타 있다.
모델 학습 방법과, k개의 어떻게 찾는지 확인해 보자..
사용된 데이타. .mass, width, height, color만 featur로 사용한다.
4개로 분류된다는 지식으로 k=4를 사용하였다. 지식이 없다면, 적당한 k를 찾아야 한다. 엘보우 방법은 대표적인 갯수를 찾는 방식이다.
이너셔(inertia)는 클러스터 샘플이 얼마나 가까운지를 나타낸다. 클러스터의 중심과 샘플사이의 거리의 제곱 합이다.
클러스터 개수가 늘어나면 클러스터 개개의 크기는 줄어들기 때문에 이너셔도 줄어든다. 엘보우 방법은 클러스터 개수를 늘려가면서 이너셔의 변화를 관찰한다.
즉, 클러스터 개수를 증가시키면서 이너지를 그래프로 그리면 감소하는 속도가 꺽이는 지점을 선택한다. 아래 그림 처럼 꺽이는 부분이 4이고, 이를 선택한다.
inertia = []
for k in range(2, 7):
km = KMeans(n_clusters=k, random_state=42)
km.fit(X_fruits_normalized)
inertia.append(km.inertia_)
plt.plot(range(2, 7), inertia)
plt.xlabel('k')
plt.ylabel('inertia')
plt.show()
PCA는 고차원의 데이터를 낮은 차원의 데이터로 바꿔줄 수 있다는 것인데, 중요한 것은 "어떻게 차원을 잘 낮추느냐" 이다. 즉, 10개의 컬럼의 데이타를 4개 또는 5개만 이용 할 수 있다.
(PCA는 선형대수를 좀 공부한 후에 정리를 해야겠네요...라이브러리만 쓰면 뭐 별게 아닌데... 왜 그럴까까지 따져 들어가려니..... 결국에 수학...... 고등수학에 머신러닝때문에 선형대수가 교과에 들어갔다고 하는데.. 긍정적이면서 불쌍해 보이기도하고...)
가령 우리에게는 아래와 같은 2차원 공간에 데이터들이 있다. 우리의 목표는 이 2차원 공간의 데이터를 1차원 공간의 데이터로 만들어 주는 것이다. ⇒차원 축소의 기본적인 컨셉. 여기에서 우리가 할수 있는 방법은 2가지 인데,
방법1 에서는 차원 x1, x2 에 냅다 데이터를 내려버렸다. 이렇게 할 경우 문제점은 내린 후에 값이 겹치는 데이터들이 많고, 아예 한 차원의 정보는 유실되게 된다. 반면 방법2 에서는 새로운 차원 (화살표) 에 데이터들을 내려줬다. 이렇게 한 결과 데이터들은 방법1에서의 문제를 어느정도 해결하게 된다. 여기서 중요한 것은 데이터들이 겹치지 않게 끔하는 화살표를 찾는 것!!!!
좌측에 사진처럼 2차원 상에서 무수히 다양한 화살표를 그릴 수 있다. 하지만 우리는 그 중 파란색 화살표 처럼 데이터를 해당 화살표에 1차원 으로 내렸을 때겹치지 않게 하는 화살표를 찾아야 한다. (longest distance) ⇒정리하자면,
수많은 화살표 들 중, 데이터 들을 화살표에 내렸을 때, 데이터가 최대한 안 겹치게, 멀리 퍼지게 하는 길이가 긴 화살표 찾기
거기에 데이터들을 투영
(2차원 이상의 경우 2차원으로 만들고자 한다면) 만약 또 하나의 화살표 만들 때 축 끼리는직각이 되어야 함, 최대한 데이터가 겹치지 않도록
이를선형대수학의 관점에서 해석하자면,
공분산 행렬에서 고유 벡터/고유값을 구하고
가장 분산이 큰 방향을 가진 고유벡터(e1) 에 입력데이터를 선형변환
고유벡터(e1) 과 직교하며, e1 다음으로 분산이 큰 e2 고유벡터에 또 선형변환.
1에서 행렬 A의 공분산 행렬의 고유벡터가 데이터가 최대한 안 겹치게, 멀리 퍼지게 하는 길이가 긴 축의 벡터가 된다.(나중에 증명) 2에서 고유값이 가장 큰 것에 매핑되는 고유 벡터(e1)가 1의 고유 벡터 중 데이터의 분산이 가장 큰(데이터가 최대한 안 겹치게, 멀리 퍼지게 하는 길이가 긴) 축의 벡터가 된다. 3에서 2의 벡터와 직교하며 다음으로 고유값이 큰(다음으로 분산이 큰) 벡터(e2)를 찾는다.
PCA에 대해 깔끔하게 정리된 글... 필요성.. 원리는 어떠한지.. (결국 선형대수 T.T)
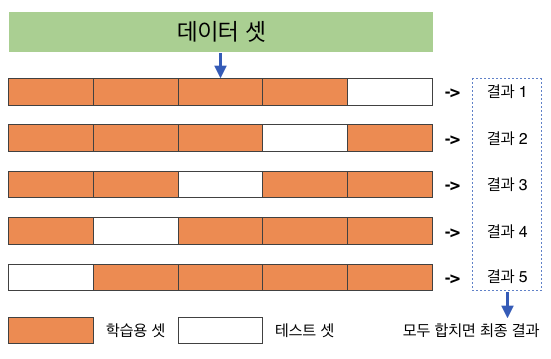
머신러닝에서도 학습 후 에 바로 시험을 볼 것이 아니라, 모의 고사를 보면 학습이 잘 될 것이다. 교차 검증은 모의 고사에 해당
일반화 성능이 높은 모델을 훈련시키기 위해 많이 사용되는 방식 중 하나가교차 검증cross validation이다. 교차 검증은 훈련 데이터셋의 일부인검증 셋validation set을 이용하여 훈련 과정중에 훈련 중인 모델의 일반화 성능을 검증하는 기법이며, 이를 통해 일반화 성능이 높은 모델을 훈련시키도록 유도한다.
테스트 데이터를 다르게 설정할 때마다 학습 데이터의 구성도 당연히 달라집니다. (위 그림에서 하얀색 칸 위치가 달라질 때마다 주황색 칸의 구성도 달라지고 있는게 보이죠.) 약간씩 다른 구성의 학습 데이터로 학습하는 모델이 총 k번 돌아가게 되는 셈이죠! 모델이 총 k번 돌아갔으니 결과물도 총 k개 나오게 되는 겁니다. 그리고 이 k개의 결과물들의 평균값이 K겹 교차 검증 방식을 활용한 모델의 성능이 되는 거죠!.
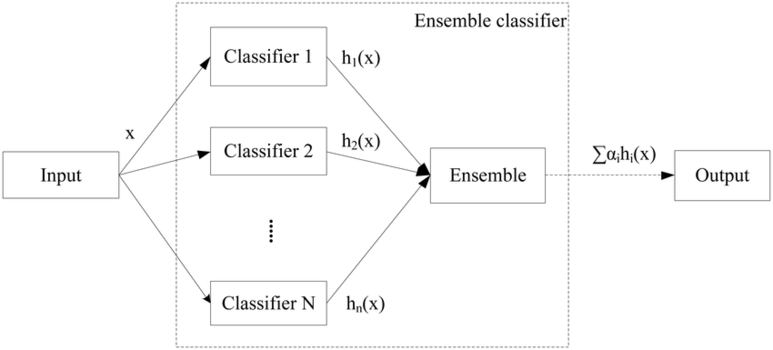
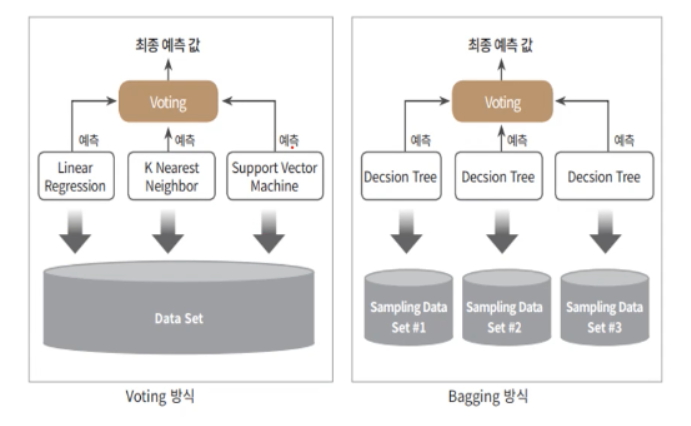
앙상블
앙상블 기법 Ensemble Learning 이란 여러 개의 개별 모델을 조합하여 최적의 모델로 일반화하는 방법입니다. weak classifier 들을 결합하여 strong classifier 를 만드는 것입니다. decision tree 에서 overfitting 되는 문제를 앙상블에서는 감소시킨다는 장점이 있습니다.