딥러닝을 이해하기 위해 지금까지 머신러닝을 공부하였구나 생각이 드네요..문제종류(회귀, 이진,다항분류..), 손실함수, 하이퍼파라미터 등..
1. 기본 개념도. 2.TensorFlow 기본 사용법.3 책의 예제로 입력/출력층으로 구성된 모델 살펴보기. 4. 다중 레이어로 구성된 모델 살펴보기로 정리를 해봤어요..
(아... cheatSheet 중간에 있음)
정리를 하다 보니 앞 부분에서 대충 넘어간 부분들을 다시 살펴볼 필요가 있네요... 그래도... 다시 봐야 하고 중점적으로 봐야 할지 느끼네... 아직 안개속에 있지만 안개가 희미하게 거치는 느낌!!!ㅎ

책을 살때의 매직.... 읽고 안 읽고는 나중 문제다.. 읽고 난 후의 모습을 상상하며 책을 산다....필독!!!
1. 주요 딥러닝 개념도
- 인간의 뇌를 본뜬 Perceptrons.. .
- 중간층은 입력값과 적절한 웨이트를 조절하여 새로운 의미의 속성을 표현한다고 개념적으로 생각하자.
- 만약 데이타가 세로, 가로라면 사람은 크기를 유추할 수 있다.
- 만약 데이타가 집의 크기, 침대 수, 우편번호, 거주자의 연봉이 있다면... 우편번호와 연봉으로 학교의 등급을 표현할 수 있다...
- 노드의 결과가 다른 노드로 전달할때 얼마의 값 으로 전달해야 할까? 활성화 함수..
- 이 노드의 결과는 다른 노드에 반영하지 말아야 해...아니야... 0.3만 반영해... 그렇지 않아... 음수로 반영해.....
- 결과 값을 찾았는데... 찾은 값이 오류가 있다고 판단을 하면,, 찾은 값을 증가 시켜야 할까?? 감소 시켜야 할까??
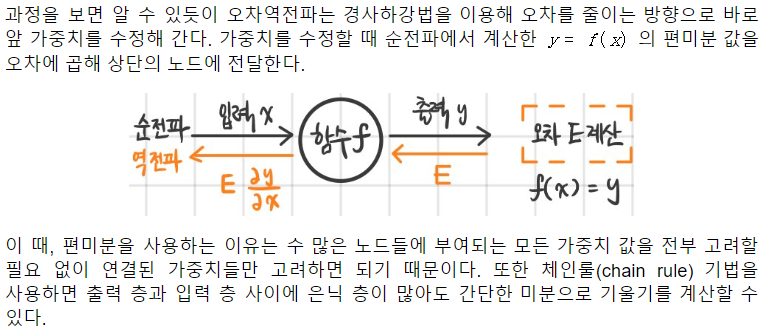
- 순전파 : 주어진 데이타로 결과를 찾는 방향...순방향
- 역전파: 결과를 찾았으면, 오류를 수정하기 위해....가중치를 수정한다..... 역방향..
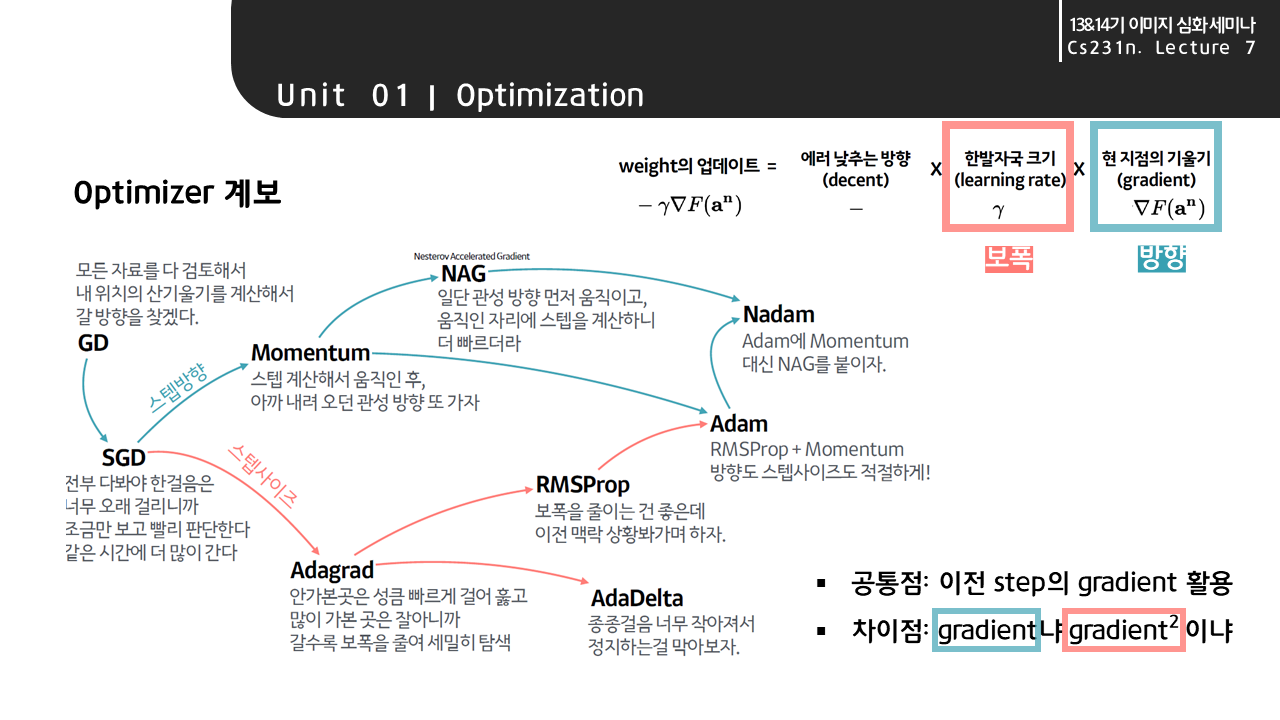
- Hyperparameters
- 은닉층의 수, 노드의 수, 활성화 함수, batch_size는 상황에 따라 지정해야 할 하이퍼 파라미터
- 다만, 결과층의 활성화 함수는 문제에 따라 정해져 있다!!
- 옵티마이저 역시 하이퍼파라미터임!!
- RMS,SGD등
- 은닉층의 수, 노드의 수, 활성화 함수, batch_size는 상황에 따라 지정해야 할 하이퍼 파라미터
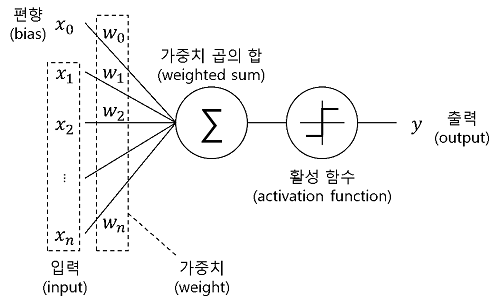
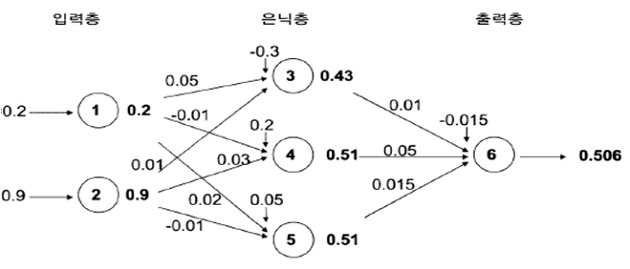
예를 들어, 0.2와 0.9 두 개의 입력 값으로 0.5라는 예측값을 도출하는 인공신경망 모델을 학습시키는 과정을 생각해보겠습니다. 아래 그림과 같이 입력층에는 2개의 노드가 할당되며 출력 층에는 1개의 노드가 할당됩니다. 그리고 은닉층은 1개이며, 은닉노드는 3개로 임의로 설정합니다. 여기서 은닉층과 은닉노드의 개수는 다수의 반복실험을 통해 사용자가 적절하게 설정해야 하는 값입니다
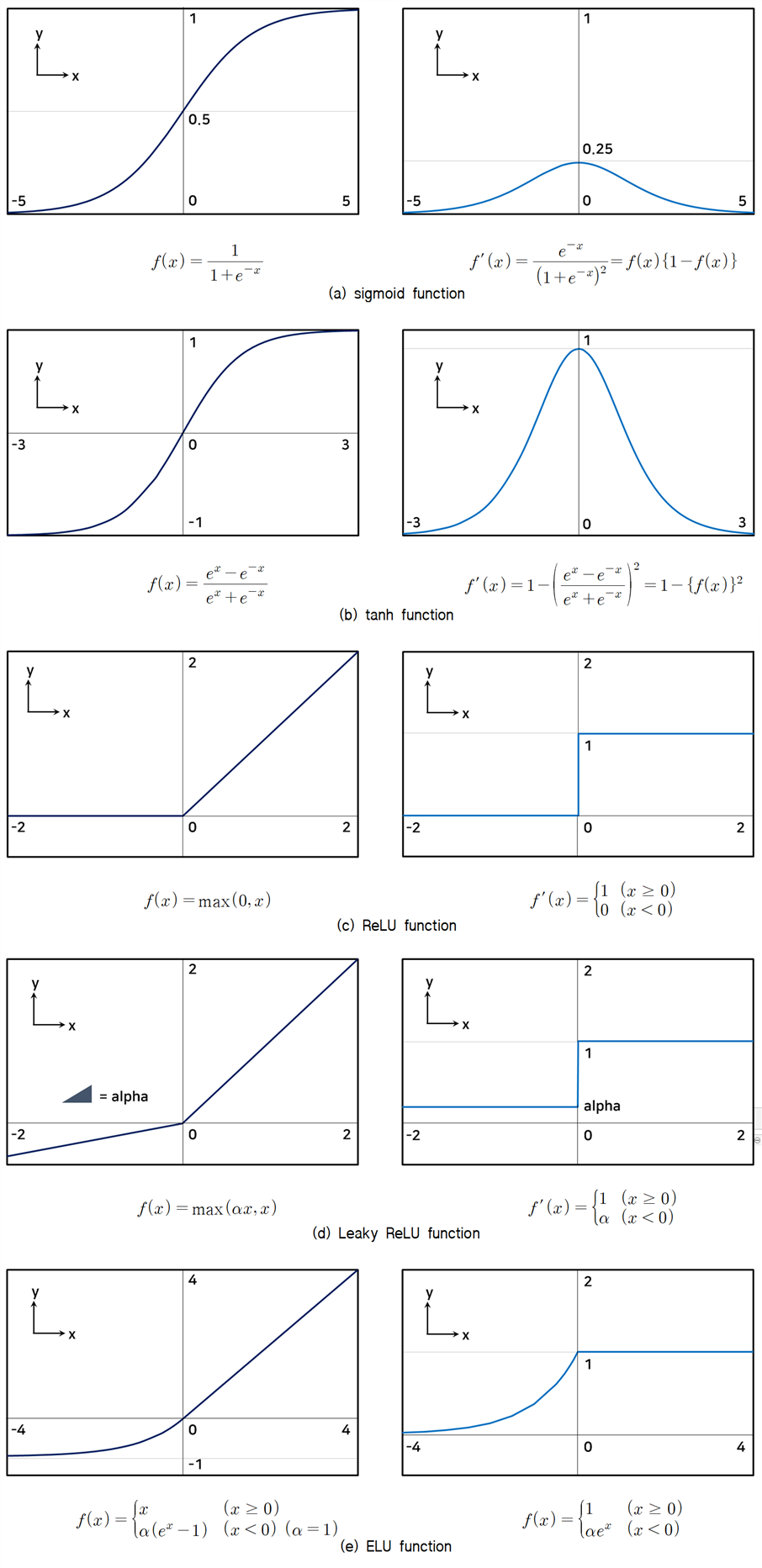
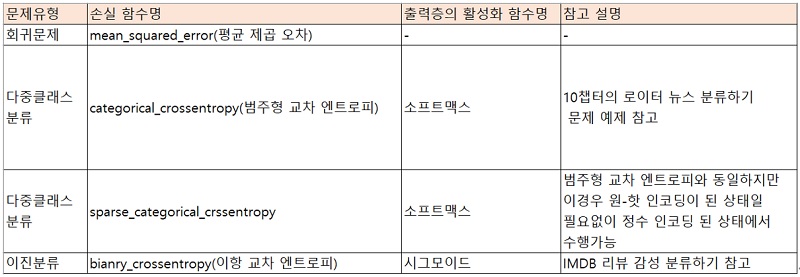
문제에 따라 사용되는 활성화 함수와 손실 함수
2. Tensorflow 기초 사용법
모델 생성이 기존 머신러닝보다 복잡합니다. 레이어를 생성해야 하고, 활성화 함수를 지정해야 하고, loss 함수등을 지정해야 하는군요... 파란색으로 표기된 모델 생성과 학습부분을 세부 공부를 해야 겠군요.
Tensorflow의 cheat sheet를 옆에 끼고 공부하기..
| TensorFlow Basic Sample (손실함수와 마지막 활성화함수를 보니..이진분류이군요) |
Machine Learning Basic Sample |
| import numpy as np from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense #데이타 생성 data = np.random.random((1000,100)) labels = np.random.randint(2,size=(1000,1)) #전처리 #모델 생성 및 학습 model = Sequential() model.add(Dense(32, activation='relu', input_dim=100)) model.add(Dense(1, activation='sigmoid')) model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['accuracy']) model.fit(data,labels,epochs=10,batch_size=32) #예측 predictions = model.predict(data) #평가 |
from sklearn import neighbors, datasets, preprocessing from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score #데이터 생성 iris = datasets.load_iris() X, y = iris.data[:, :2], iris.target X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=33) #전처리 scaler = preprocessing.StandardScaler().fit(X_train) X_train = scaler.transform(X_train) X_test = scaler.transform(X_test) #모델 생성 및 학습 knn = neighbors.KNeighborsClassifier(n_neighbors=5) knn.fit(X_train, y_train) #예측 y_pred = knn.predict(X_test) # 평가 accuracy_score(y_test, y_pred) |
3. MNIST 패선 다중 클래스 분류
10종류의 60,000개의 그림을 분류 하는 예제. 하나의 그림은 28*28 크기의 2차원 데이타를 1차원으로 변환하여 사용함. 즉 그림 하나는 784 = 28*28 크기임

입력은 784, 히든 층 없이 결과층을 node=10로 만듭니다.
다중 클라스 분류이므로 sparse+categorical_crossentropy를 사용하고 출력층의 활성화 함수는 softmax를 사용합니다.
import tensorflow as tf
from tensorflow import keras
from sklearn.model_selection import train_test_split
from tensorflow.keras.utils import *
# 실행마다 동일한 결과를 얻기 위해 케라스에 랜덤 시드를 사용하고 텐서플로 연산을 결정적으로 만듭니다.
tf.keras.utils.set_random_seed(42)
tf.config.experimental.enable_op_determinism()
#데이타 갖고 오기
(train_input, train_target), (test_input, test_target) = keras.datasets.fashion_mnist.load_data()
#전처리...
#1. scaling
train_scaled = train_input / 255.0
#2. 데이타를 1차원으로 변경하기
train_scaled = train_scaled.reshape(-1, 28*28)
#데이타 사이즈 확인
print(f'데이타 크기 {train_scaled.shape}, 정답 크기{train_target.shape}')
# 학습/평가데이타 분류
train_scaled, val_scaled, train_target, val_target = train_test_split(
train_scaled, train_target, test_size=0.2, random_state=42)
# 모델 생성
dense = keras.layers.Dense(10, activation='softmax', input_shape=(784,))
model = keras.Sequential(dense)
model.compile(loss='sparse_categorical_crossentropy', metrics='accuracy')
# 모델 요약 정보 조회
model.summary()
plot_model(model, show_layer_names=False, show_shapes=True)
#모델 학습
history= model.fit(train_scaled, train_target, epochs=5)
#모델 평가
model.evaluate(val_scaled, val_target)
다음 함수로 Layer를 그려봅니다.
plot_model(model, show_layer_names=False, show_shapes=True)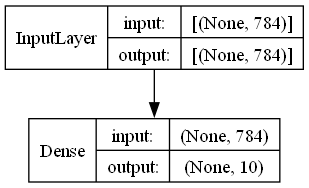
다음 함수로 파라미터를 포함한 model을 확인합니다.
Dense Layer는 784개의 입력을 받아서 10개의 노드로 전달하고, 노드 수만큼의 편향이 있어서.. 784 * 10 + 10 = 7850이 되는 것을 알 수 있습니다.
즉 각 레이어의 파라미터는 입력수 * 노드 수 + 노드수임을 알 수 있습니다.
데이타 크기 (60000, 784), 정답 크기(60000,)
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 10) 7850
=================================================================
Total params: 7850 (30.66 KB)
Trainable params: 7850 (30.66 KB)
Non-trainable params: 0 (0.00 Byte)
가령, 입력이 100개 이고, 미집층에 있는 뉴런 개수가 10개일때 필요 파라미터는 입력수 * 노드 수 + 노드수이므로 100 * 10 +10 = 1010임을 알 수 있습니다.
정말 맞을까요?? 코드로 확인해보죠.. ^^
먼저 결과 입니다. 손으로 계산한 1010과 코드로 출력한 결과가 100잘 나왔습니다.
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_1 (Dense) (None, 10) 1010
=================================================================
Total params: 1010 (3.95 KB)
Trainable params: 1010 (3.95 KB)
Non-trainable params: 0 (0.00 Byte)
___________________________________________________
입력에 대한 갯수가 없어 100개 입력을 했는지 확인해 보겠습니다. 출력을 보니 맞군요..
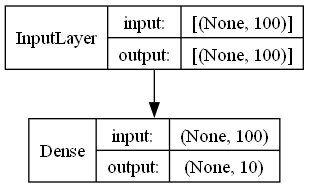
사용된 코드는 아래와 같습니다.
# 모델 생성
dense = keras.layers.Dense(10, activation='softmax', input_shape=(100,))
model = keras.Sequential(dense)
model.compile(loss='sparse_categorical_crossentropy', metrics='accuracy')
# 모델 요약 정보 조회
model.summary()
# 모델 그림 그리기
plot_model(model, show_layer_names=False, show_shapes=True)
4. MNIST 패선 다중 클래스 분류 (다중 레이어)
- 하이퍼 파라미터인 은닉층 및 옵티마이저 추가하기
- 데이타가 28* 28 크기의 2차원 데이타를 Flatten Layer를 사용하여 2차원 데이타를 사용하기
- 3장에서는 np를 사용
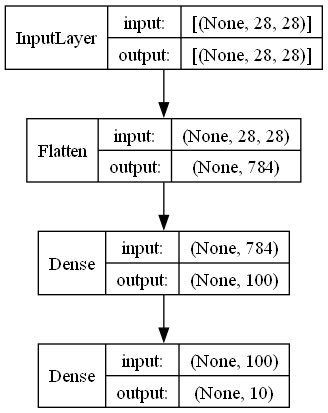
import tensorflow as tf
from tensorflow import keras
from sklearn.model_selection import train_test_split
from tensorflow.keras.utils import *
# 실행마다 동일한 결과를 얻기 위해 케라스에 랜덤 시드를 사용하고 텐서플로 연산을 결정적으로 만듭니다.
tf.keras.utils.set_random_seed(42)
tf.config.experimental.enable_op_determinism()
#데이타 갖고 오기
(train_input, train_target), (test_input, test_target) = keras.datasets.fashion_mnist.load_data()
#전처리...
#1. scaling
train_scaled = train_input / 255.0
#데이타 사이즈 확인
print(f'데이타 크기 {train_scaled.shape}, 정답 크기{train_target.shape}')
# 학습/평가데이타 분류
train_scaled, val_scaled, train_target, val_target = train_test_split(
train_scaled, train_target, test_size=0.2, random_state=42)
# 모델 생성
model = keras.Sequential()
##데이타를 1차원으로 변경하기
## train_scaled.reshape(-1, 28*28) 대신 Flatten()를 사용한다.
model.add(keras.layers.Flatten(input_shape=(28, 28)))
model.add(keras.layers.Dense(100, activation='relu'))
model.add(keras.layers.Dense(10, activation='softmax'))
## Optimizer를 사용한다.
sgd = keras.optimizers.SGD()
model.compile(optimizer=sgd, loss='sparse_categorical_crossentropy', metrics='accuracy')
# 모델 요약 정보 조회
model.summary()
plot_model(model, show_layer_names=False, show_shapes=True)
#모델 학습
history= model.fit(train_scaled, train_target, epochs=5)
#모델 평가
model.evaluate(val_scaled, val_target)
참고자료
https://www.hani.co.kr/arti/science/science_general/755976.html
1000억개 뉴런, 100조개 시냅스…이들은 기억에서 무슨 일할까
기억에 관한 연구 결과가 종종 뉴스로 보도됩니다. 기억을 다룬 과학 뉴스를 좀더 흥미롭게 보려면 신경과학의 몇 가지 용어에 익숙해지는 게 좋습니다. 기억은 뇌 신경세포와 시냅스에 저장된
www.hani.co.kr
https://www.lgcns.com/blog/cns-tech/ai-data/14558/
인공신경망이란 무엇인가? - LG CNS
2016년 3월, 세계적으로 큰 이슈를 몰고 온 게임이 성사되었습니다. 그것은 바로 세계 최고 바둑기사인 대한민국의 이세돌과 구글 딥마인드의 인공지능 바둑 프로그램 알파고(alphago)와의 대결인
www.lgcns.com
[딥러닝] 핵심 개념&핵심 용어 쉽게 알아보자! (가능한)
안녕하세요, 오늘 주제는 [딥러닝]입니다.
jalynne-kim.medium.com
https://velog.io/@denev6/neural-network
velog
velog.io
https://github.com/hunkim/DeepLearningZeroToAll?tab=readme-ov-file
GitHub - hunkim/DeepLearningZeroToAll: TensorFlow Basic Tutorial Labs
TensorFlow Basic Tutorial Labs. Contribute to hunkim/DeepLearningZeroToAll development by creating an account on GitHub.
github.com
https://blog.skby.net/%EC%9D%B8%EA%B3%B5%EC%8B%A0%EA%B2%BD%EB%A7%9D-artificial-neural-network/
인공신경망 (Artificial Neural Network) < 도리의 디지털라이프
I. 분류와 예측 모형, 인공신경망, ANN 가. 인공신경망의 개념 인간의 뉴런을 모방하여 가중치 조정을 통한 분류와 예측을 위해 다수 노드를 연결한 계층적 조직 나. 인공신경망의 특징 특징 구성
blog.skby.net
velog
velog.io
https://www.holehouse.org/mlclass/
Machine Learning - complete course notes
Stanford Machine Learning The following notes represent a complete, stand alone interpretation of Stanford's machine learning course presented by Professor Andrew Ng and originally posted on the ml-class.org website during the fall 2011 semester. The topic
www.holehouse.org
'머신러닝 > 혼공 머신러닝' 카테고리의 다른 글
| [혼공머신] 11기 6주가 끝이 났다. (2) | 2024.02.08 |
|---|---|
| [혼공머신] 5주차 비지도 학습 (0) | 2024.02.03 |
| [혼공머신] 4주차 트리 알고리즘 (2) | 2024.01.31 |
| [번외] Encoding의 필요성 (0) | 2024.01.31 |
| Resources (0) | 2024.01.31 |