0. 잘 정리가 된 글
https://www.itworld.co.kr/news/307189
“LLM 개발을 더 간편하게” 랭체인(LangChain)의 이해
대규모 언어 모델(LLM)을 위한 효과적인 프롬프트를 작성하는 데는 기술이 필요하지만 LLM 사용법은 대체로 간단하다. 반면 언어 모델을 사용한
www.itworld.co.kr
10분 만에 RAG 이해하기
AI의 새로운 핫 토픽 RAG(검색-증강 생성)를 설명해 드립니다. | 소프트웨어 산업에는 하루에도 수십 개의 새로운 약어와 개념이 등장합니다. 특히나 빠르게 변하는 AI 기술 같은 경우라면 더욱 말
brunch.co.kr
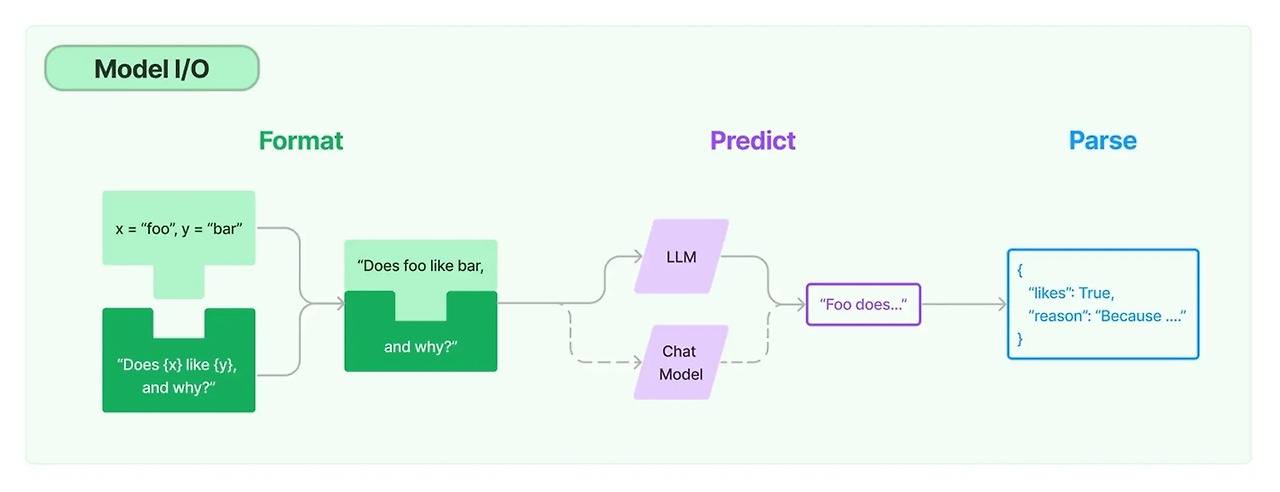
1. 모델 I/O는 프롬프트를 관리하고 공통 인터페이스를 통해 언어 모델을 호출하고 모델 출력에서 정보를 추출할 수 있게 해준다
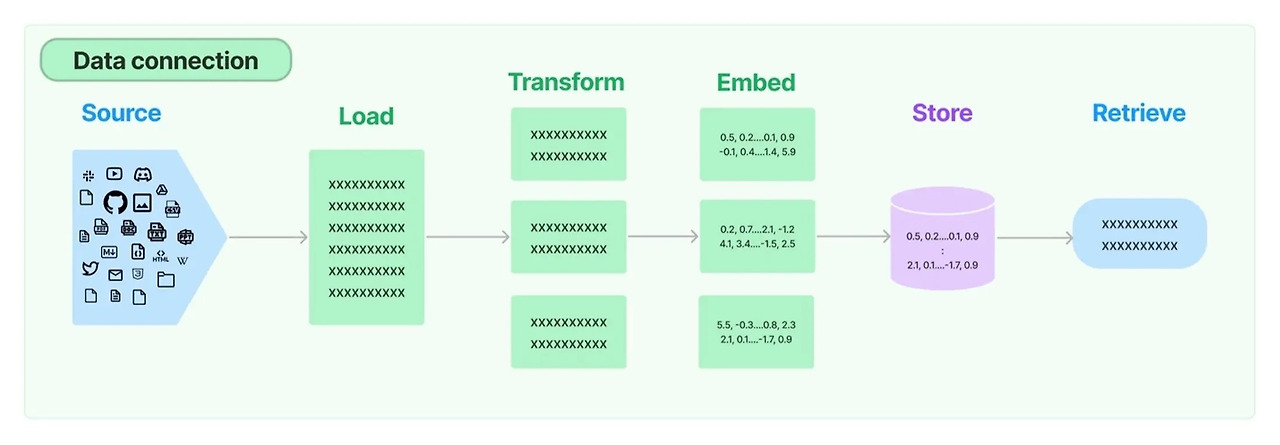
2. 데이터 연결은 데이터를 로드, 변형, 저장 및 쿼리하기 위한 빌딩 블록을 제공한다
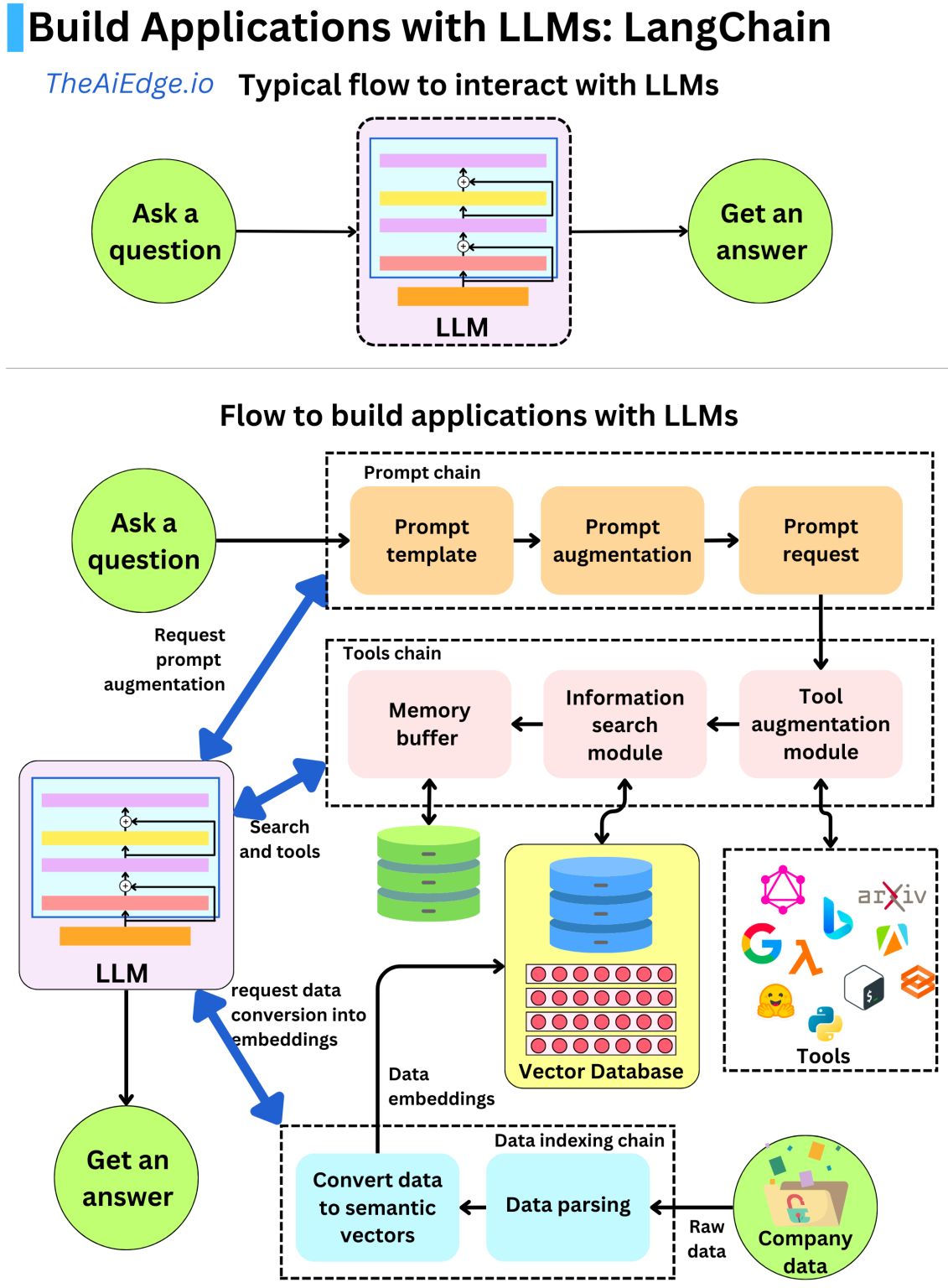
3. Chain : 구성 요소를 조합해서 하나의 파이프라인을 구성한다.
4. 메모리
메모리는 데이터를 저장하는 공간. 데이터는 대화과정에서 발생하는 데이터를 의미.
챕봇 앱은 이전 대화를 기억해야 하지만, LLM은 채팅 기록을 장ㅇ기적으로 ㅂ관하지 않는다.
대화 내용은 다음과 같은 형태로 저장될 수 있다.
- Conversation Buffer: 그동안의 모든 대화를 저장한다. 대화가 길어질 수록 메모리 용량이 증가한다는 점이 단점이다.
- Conversation Buffer Window: 마지막 k개의 대화만 저장한다. 최근 대화만 저장하기에 메모리 용량이 과도하게 늘어나지 않는다는 장점이 있지만, 이전 내용을 잊게 된다는 단점이 있다.
- Conversation Summary: LLM을 사용하여 대화 내용을 요약하며 저장한다.
- Conversation Summary Buffer: max_token_limit을 초과할 경우에 요약하여 저장한다. Buffer Window와 Summary의 결합이다.
- Conversation Knowledge Graph: 대화 속 주요 entity를 추출해 지식 그래프(knowledge graph)를 생성한다.
https://blog.futuresmart.ai/langchain-memory-with-llms-for-advanced-conversational-ai-and-chatbots
Langchain Memory with LLMs for Advanced Conversational AI and Chatbots
Explore the concept and types of Langchain memory, and learn how to integrate it with Streamlit and OpenAI's GPT API to build smarter, context-aware chatbot
blog.futuresmart.ai
LLAMA3 RAG 시스템: AI 어시스턴트로 10초만에 자동 보고서 만들기
안녕하세요! 오늘은 요즘 가장 인기 있는 언어 모델, LLAMA3로 AI 어시스턴트를 만들어 보겠습니다. 이 앱은 Groq과 Phidata를 이용해서 주어진 웹 사이트나 pdf를 기반으로 "원클릭" 보고서를 작성하고
fornewchallenge.tistory.com
'머신러닝 > RAG' 카테고리의 다른 글
| 1. Local LLM에 대하여 (0) | 2024.04.12 |
|---|---|
| 0 환경 설정 - ollama 설치 (0) | 2024.04.10 |