decsion tree 알고리즘이 feature를 선택하여 분류하는지 따라가다보니 모델의 cost func()까지 찾아가보게 되었군요...
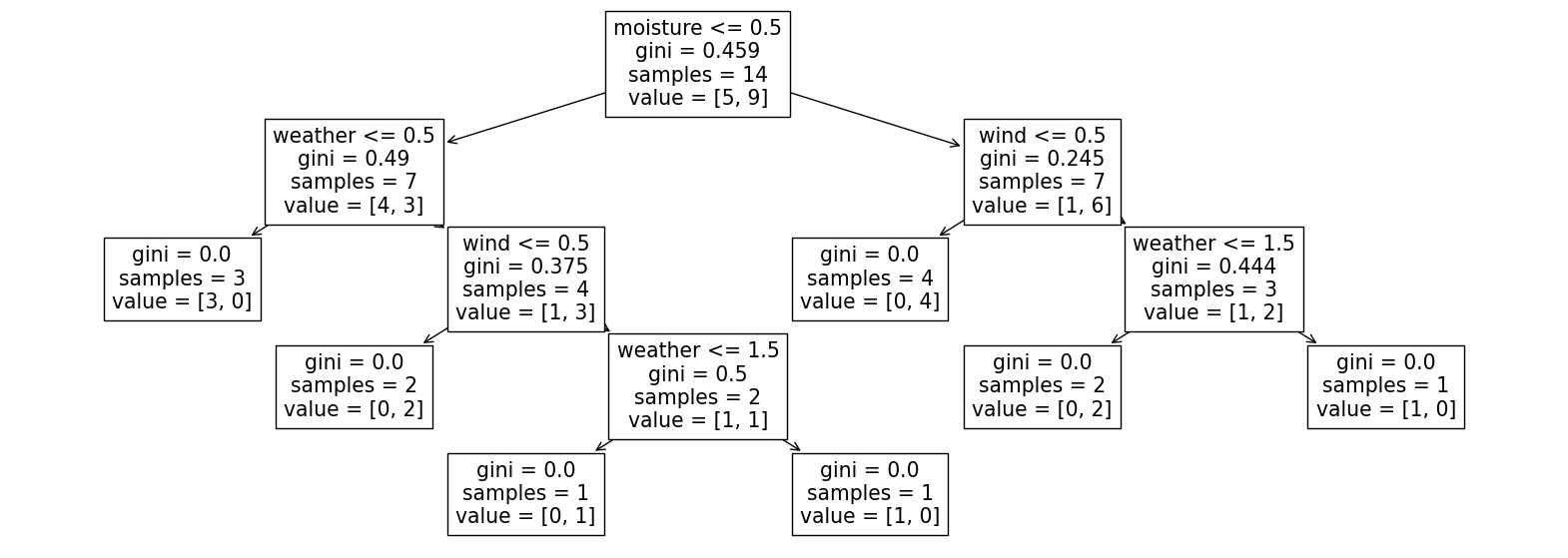
이번주 궁금한 것이 decision tree에서 분명 수식으로 계산된 값은 틀린것이 없는데 model 학습된 tree와 일치하지 않는 것이 있습니다. 소스와 데이타를 공유하니.. 무엇이 잘못되었는지 뎃글 공유해 주시면....감사하겠습니다.
(직접 계산하면 첫번째 노드가 날씨부터 분류, model의 첫번째 노드는 습도부터 분류합니다. 계산으로 유도된 노드인 날씨가 맞는것 같은데... 모델은 왜 습도를 먼저 선택했을까가 궁금합니다. 데이타 변환이 잘못된것인가 하는 의심이 듭니다만..)
One-Hot Encoding의 필요성을 느낍니다..
https://hoyokin.tistory.com/33
의사결정트리(Decision Tree)란?
- 의사결정트리는 일련의 분류 규칙을 통해 데이터를 분류, 회귀하는 지도 학습 모델 중 하나이며,
- 결과 모델이 Tree 구조를 가지고 있기 때문에 Decision Tree라는 이름을 가집니다.
- 아래 그림을 보면 더 쉽게 이해가 가능합니다.

- 위 그림은 대표적인 의사결정트리의 예시로서, 타이타닉호의 탑승객의 생존여부를 나타내고 있습니다.
- 이렇게 특정 기준(질문)에 따라 데이터를 구분하는 모델을 의사 결정 트리 모델이라고 합니다.
- 한번의 분기 때마다 변수 영역을 두 개로 구분합니다.
- 결정 트리에서 질문이나 정답은 노드(Node)라고 불립니다.
- 맨 처음 분류 기준을 Root Node라고 하고
- 중간 분류 기준을 Intermediate Node
- 맨 마지막 노드를 Terminal Node 혹은 Leaf Node라고 합니다.
- 결정 트리의 기본 아이디어는, Leaf Node가 가장 섞이지 않은 상태로 완전히 분류되는 것, 즉 복잡성(entropy)이 낮도록 만드는 것입니다.


- 주어진 문제들은 n개의 feature가 주어지고, 어떤 class에 속하는지를 decision tree model이용
- decision tree는 feature를 어떻게 tree를 만들까? Gini, Entrypy를 이용함
- GiNI 계수 확인하기
- length, width라는 2개의 feature로 세토사,버시컬러,버지니카 3개 class 분류 예제
- 아래 그림은 model이 제공하는 tree임... 각 node의 gini 계수를 구할 수 있어야 함.
- 지니 계수 $$ G_i = 1 - \sum_{k=1}^K (p_{i,k})^2 $$
- $$ p_{i,k} $$ 는 i 번째 노드에 있는 훈련 샘플 중 클래스 k에 속한 샘플의 비율, K는 클래스의 총 개수
- gini = 0.168 = $$ 1 - (p_{2,세토사}) ^2 -(p_{2,버시컬러}) ^2 - (p_{2,버지니카}) ^2 $$ = $$ 1- (0/54)^2 - (49/54)^2 - (5/54)^2 $$

- 그러면 어떻게 decision tree는 분류 할까? 아래 비용함수를 최소화 하는 feature \( k \) 와 해당 특성의 임계값 \( t_k \)를 결정해서 분할하는 과정을 반복한다.
- \( m, m_{left}, m_{right} \) : 각각 부모와 왼쪽, 오른쪽 자식 노드에 속한 샘플 개수
- \( G_{left}, G_{right} \) : 각각 왼쪽, 오른쪽 사식 노드의 지니 불순도
- $$ J(k,t_k) = \frac{m_{left}}{m}G_{left} + \frac{m_{right}}{m}G_{right} $$
- 간단한데.. 인터넷에 돌아다니는 아래 예제를 꼬오옥 확인하자!!!
- 지니계수로 비용함수를 최소화 하는 예제(중간쯤나이,수입,학생여부,신용등급에따른 컴퓨터구입여부)
- Entryp로 node를 결정하는 예제( 중간쯤테니스 경기 참가여부)
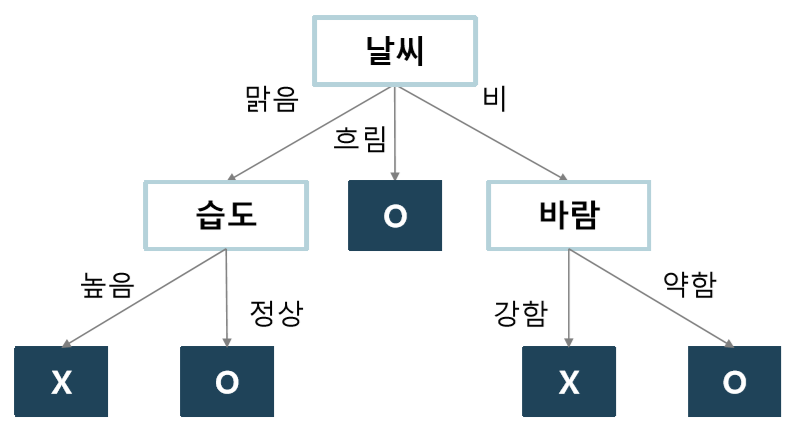
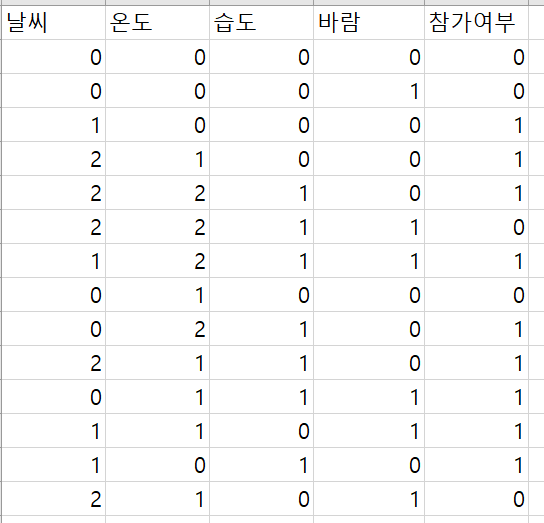
의사결정트리(Decision Tree) - 분할 실습
- https://wooono.tistory.com/104 예제를 통해 손으로 계산 해보자!!!
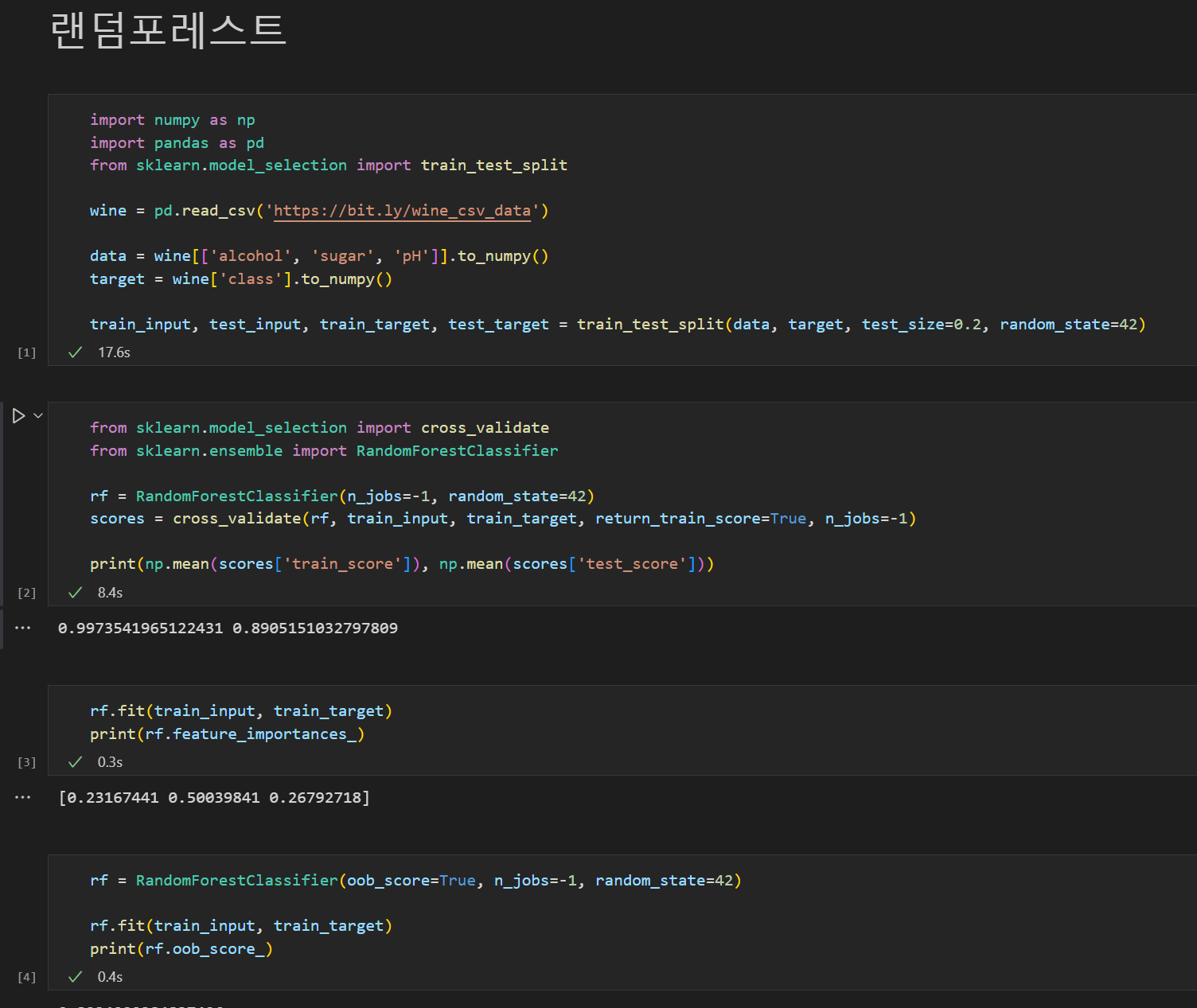
- 손으로 계산을 하면 날씨부터 분류를 해야 한다. 모델로 학습을 하면 습도부터 분류를 한다... 소스코드를 제공하니 무엇이 잘못되었는지 확인부터!!


교차 검증
- 수능 시험을 보기 위해 학습하고, 모의 고사 시험을 몇 번 보고, 한번의 수능을 본다,
- 머신러닝에서도 학습 후 에 바로 시험을 볼 것이 아니라, 모의 고사를 보면 학습이 잘 될 것이다. 교차 검증은 모의 고사에 해당
- 일반화 성능이 높은 모델을 훈련시키기 위해 많이 사용되는 방식 중 하나가 교차 검증cross validation이다. 교차 검증은 훈련 데이터셋의 일부인 검증 셋validation set을 이용하여 훈련 과정중에 훈련 중인 모델의 일반화 성능을 검증하는 기법이며, 이를 통해 일반화 성능이 높은 모델을 훈련시키도록 유도한다.
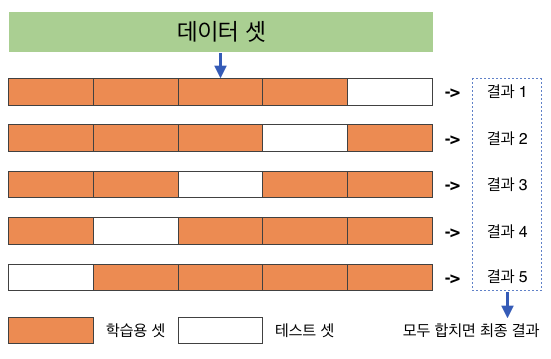
- 테스트 데이터를 다르게 설정할 때마다 학습 데이터의 구성도 당연히 달라집니다. (위 그림에서 하얀색 칸 위치가 달라질 때마다 주황색 칸의 구성도 달라지고 있는게 보이죠.) 약간씩 다른 구성의 학습 데이터로 학습하는 모델이 총 k번 돌아가게 되는 셈이죠! 모델이 총 k번 돌아갔으니 결과물도 총 k개 나오게 되는 겁니다. 그리고 이 k개의 결과물들의 평균값이 K겹 교차 검증 방식을 활용한 모델의 성능이 되는 거죠!.
앙상블
앙상블 기법 Ensemble Learning 이란 여러 개의 개별 모델을 조합하여 최적의 모델로 일반화하는 방법입니다. weak classifier 들을 결합하여 strong classifier 를 만드는 것입니다. decision tree 에서 overfitting 되는 문제를 앙상블에서는 감소시킨다는 장점이 있습니다.
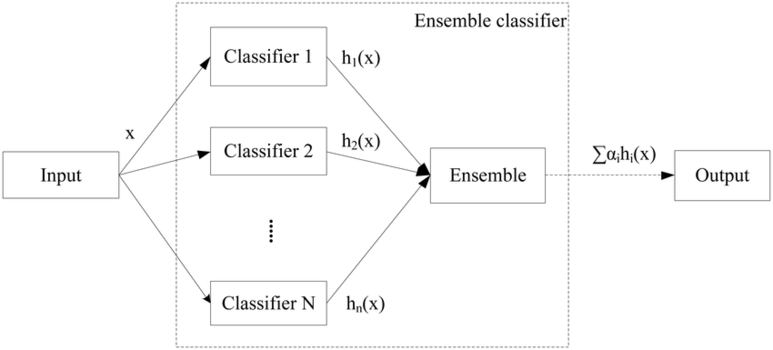
대표적으로 Random Forest 모델이 있습니다.
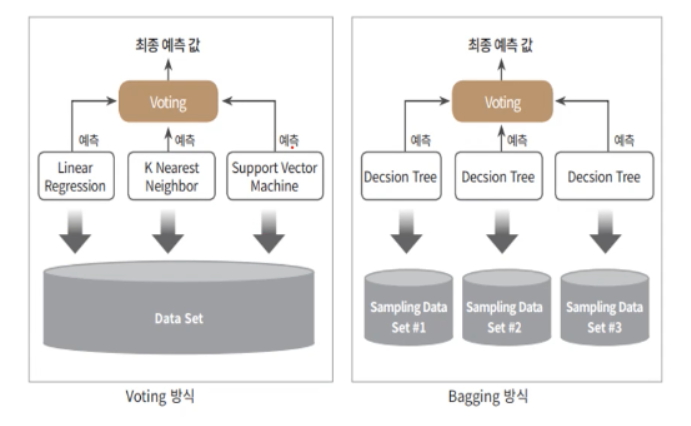
[머신러닝] 앙상블 학습 이란
앙상블 기법 Ensemble Learning 이란 여러 개의 개별 모델을 조합하여 최적의 모델로 일반화하는 방법입니다.
medium.com
'머신러닝 > 혼공 머신러닝' 카테고리의 다른 글
| [혼공머신] 6주차 딥러닝 (0) | 2024.02.06 |
|---|---|
| [혼공머신] 5주차 비지도 학습 (0) | 2024.02.03 |
| [번외] Encoding의 필요성 (0) | 2024.01.31 |
| Resources (0) | 2024.01.31 |
| [번외] Pandas 함수의 axis 파라미터 정리 (0) | 2024.01.31 |